
Cluster 란?
Clustered Index는 단어뜻을 생각해보면 군집화된 인덱스이다. 즉 실제 데이터가 인덱스와 군집되어있다는 뜻이다.
클러스터링 인덱스와 넌 클러스터링 인덱스는 두 인덱스 모두 데이터베이스에서 데이터의 접근 속도를 높이기 위해 사용한다.

위 처럼 데이터가 들어오는데로 삽입된 상황의 테이블 구조가 있다고 가정해보자.
위 테이블은 인덱스가 적용이 안된 한국인이 자주 시켜먹는 배달 순위를 나타낸 Table이다.
클러스터형 인덱스
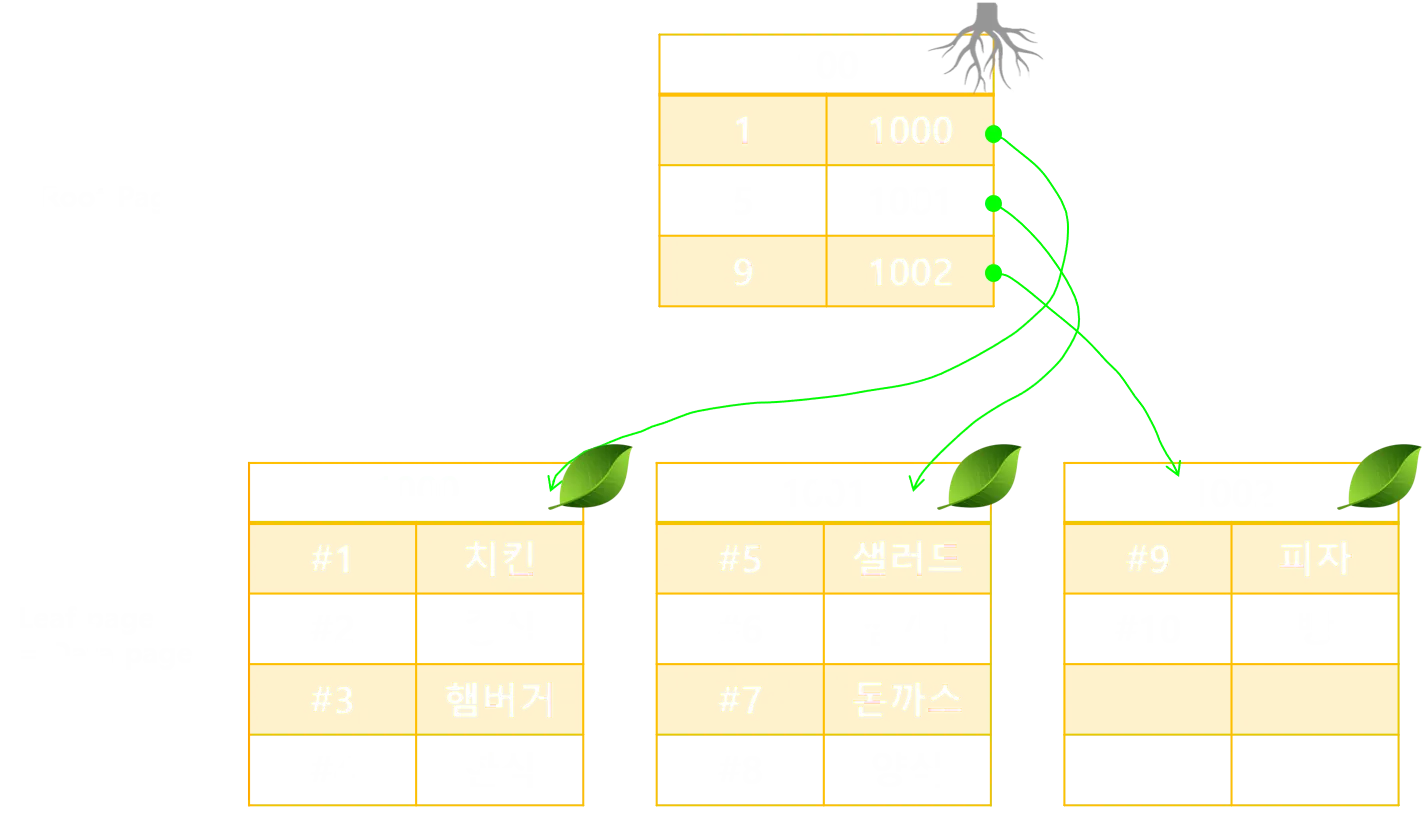
클러스터형 인덱스는 테이블 전체가 정렬된 인덱스가 되는 방식의 인덱스 종류이다. 인덱스에 따라 데이터가 지정된 열에 맞춰서 자동정렬되고 테이블 당 한개만 생성이 가능하다. innoDB에서는 디볼트 기본키를 기준으로 클러스터링되어 저장된다. 또는 Unique + Not null로 지정된 컬럼도 클러스터형 인덱스가 생성될 수 있다. (하지만 기본키가 더 우선권을 갖음)
위 그림처럼 B+Tree 형태로 구성되어있고 순위를 나타내는 컬럼을 PK로 설정해 클러스터형 인덱스를 만든 형태이다.
루트페이지가 Key값으로 PK를 가지고 있고 다른페이지의 번호를 포인터로 지니고 있다. 이러한 구조는 검색 속도를 빠르게 하지만, 생성, 업데이트, 삭제 부분에서는 새로 정렬을 해야하므로 느릴 수 밖에 없다.
넌클러스터형 인덱스
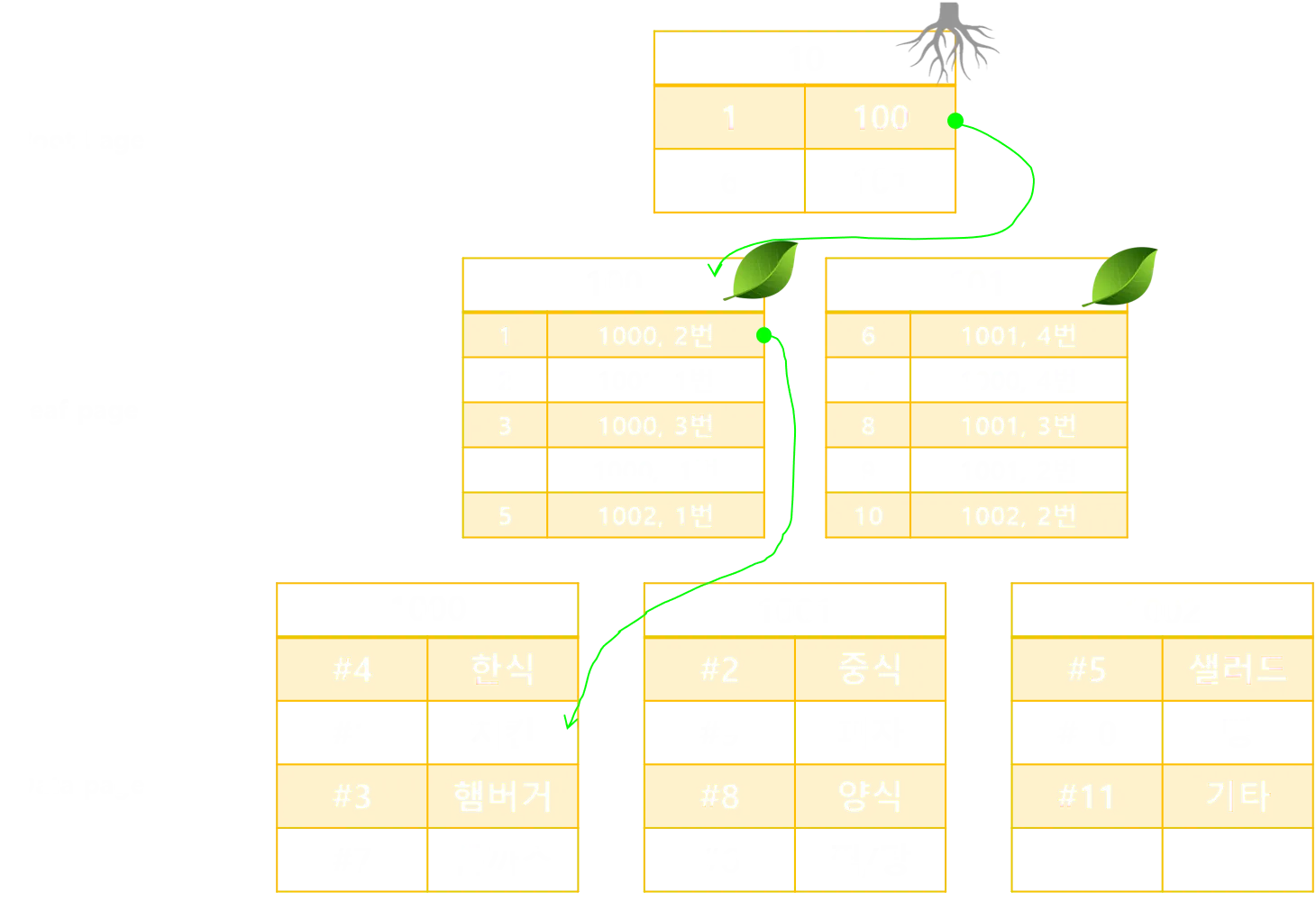
넌클러스터형 인덱스는 원본 데이터 페이지 그대로 유지하고 별도의 페이지에 넌 클러스터형 인덱스를 구성한다. 클러스터형 보다 검색속도는 느리지만 CUD는 빠르다. 데이터를 직접가리키는 것이 아닌 데이터의 위치를 가리키는 포인터 이기 떄문이다. 클러스터형과 다르게 여러개 생성 가능하다.
위그림을 보면 리프페이지에서 직접적으로 데이터를 가지고 있는 것이 아닌 데이터 페이지 번호와 해당 행의 위치를 저장하고 있다. 인덱스 페이지(Root + Leaf)는 정렬되어있으나 DATA page는 처음에 저장했던 순서 그대로이다.
혼합된 클러스터형 인덱스 + 넌 클러스터형 인덱스
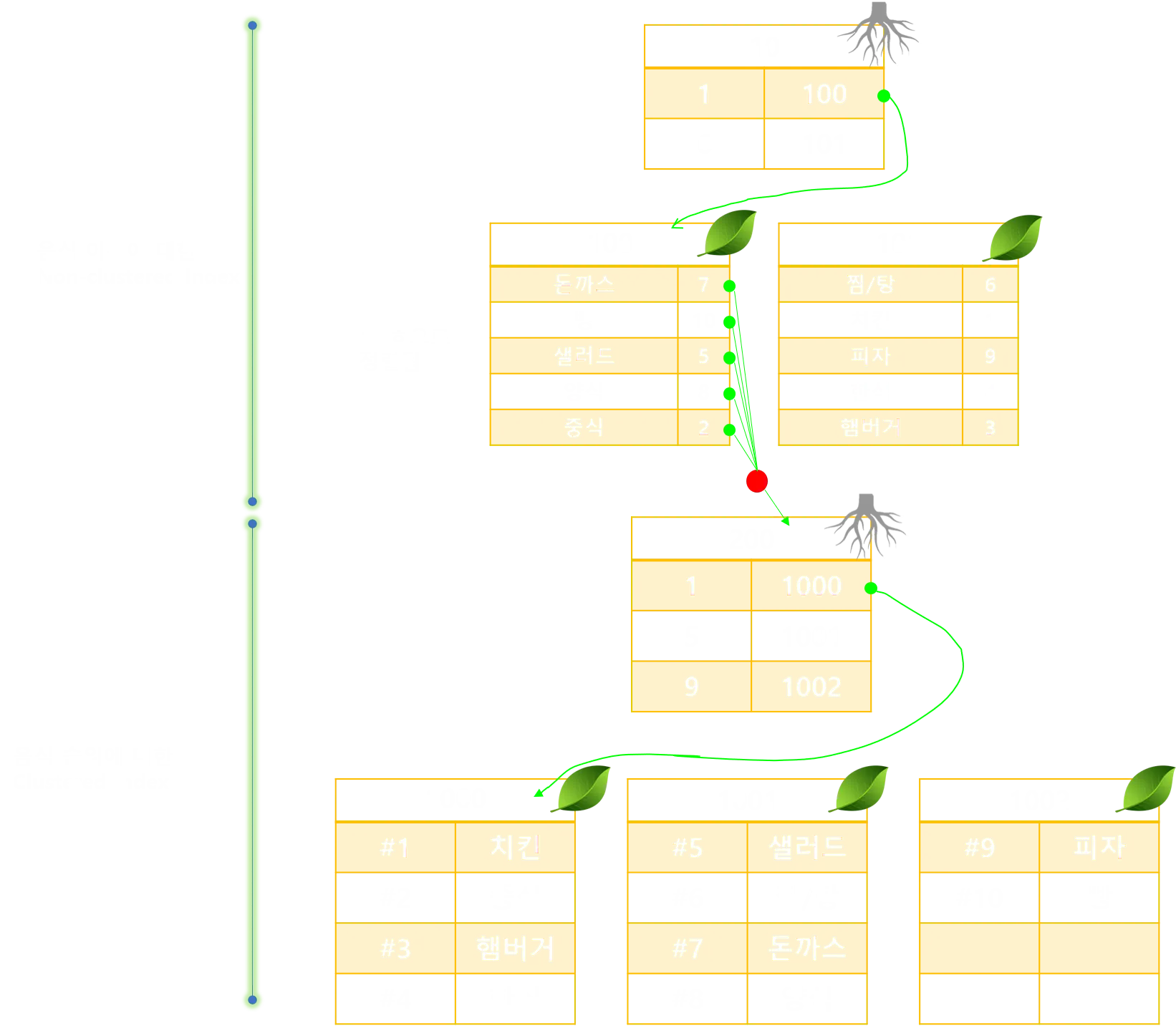
보통 인덱스 처리를 할때, 위와같이 혼합해서 사용하는 경우가 많다. PK는 기본적으로 존재해야 테이블을 생성할 수 있고, 추가로 조회가 자주 발생하는 부분에 대해 인덱스를 처리하기 떄문이다. 이럴경우 위와같은 구조로 작동한다. 순위에대해 PK를 지정하고 음식에 대해 클러스터형 인덱스를 설정한 모습이다.
넌클러스터형에 왜 PK값을 넣는거죠? 일 두번하는 거 아닌가요? 라는 의문이 생길수 있다. 물론 조회만 일어나면 맞는말이지만, 만약에 테이블에 1순위가 스테이크 로 바뀌고 치킨이 11위로 밀렸다고 가정해보자. 기존의 경우에는 아래의 클러스터 인덱스 부분들만 정렬하고 음식 인덱스에 대해서는 값만 추가해주면 된다. 하지만 넌클러스터형의 예시처럼 데이터페이지의 주소와 값을 가지고 있다면 넌 클러스트형 인덱스까지 모두 수정해야하는일이 발생한다.
사실, 기본키값인 순위가 변동성이 큰 값이라 해당 예시가 적절지 못할수도 있다고 생각한다. 하지만, 핵심은 이렇게 간접적으로 데이터를 가짐으로써 인덱스의 이점과 CUD가 왔을때 최악의 상황을 방지하는 방지턱의 역할로 이해하면 좋을꺼 같다.